
Masterplan to PhD
Research Focus
My PhD research focuses on Human-Robot Interaction (HRI), specifically on improving Human-Robot Conversations (HRC) through visual models. The goal is to enhance Visual Voice Activity Detection (VVAD) and Active Speaker Detection(ASD) to make them robust and applicable in HRI scenarios. This involves addressing several dimensions:
- Transitioning from single-person(VVAD) to multi-person(ASD) interactions.
- Exploring input sizes, ranging from:
- Lip Features -> Face Features -> Lip Images -> Face Images -> Full Images.
- Producing outputs such as:
- Speaking/Not Speaking Labels and
- Bounding Boxes for active speakers.
- optionally: Exploring multimodal Models for Audio-Visual Voice Activity Detection and Active Speaker Detection
Research Pillars
My PhD research is structured around three main pillars:
1. Data
This pillar focuses on the VVAD-LRS3 dataset, which I have created, and the associated pipelines for working with the data. These pipelines ensure efficient data preprocessing, augmentation, and management to support robust model training.
2. Models
This pillar involves the development and training of models using the VVAD-LRS3 and other datasets. It also includes the algorithms for pre- and post-processing, as well as the implementation efforts to make these models accessible. This includes:
- Optimized training pipelines.
- Scalable and efficient model architectures.
- Tools and libraries to facilitate easy integration.
3. Application
This pillar focuses on the use cases where the models are applied. It includes conducting experiments to validate the models in real-world scenarios and exploring their utility in various Human-Robot Interaction (HRI) contexts.
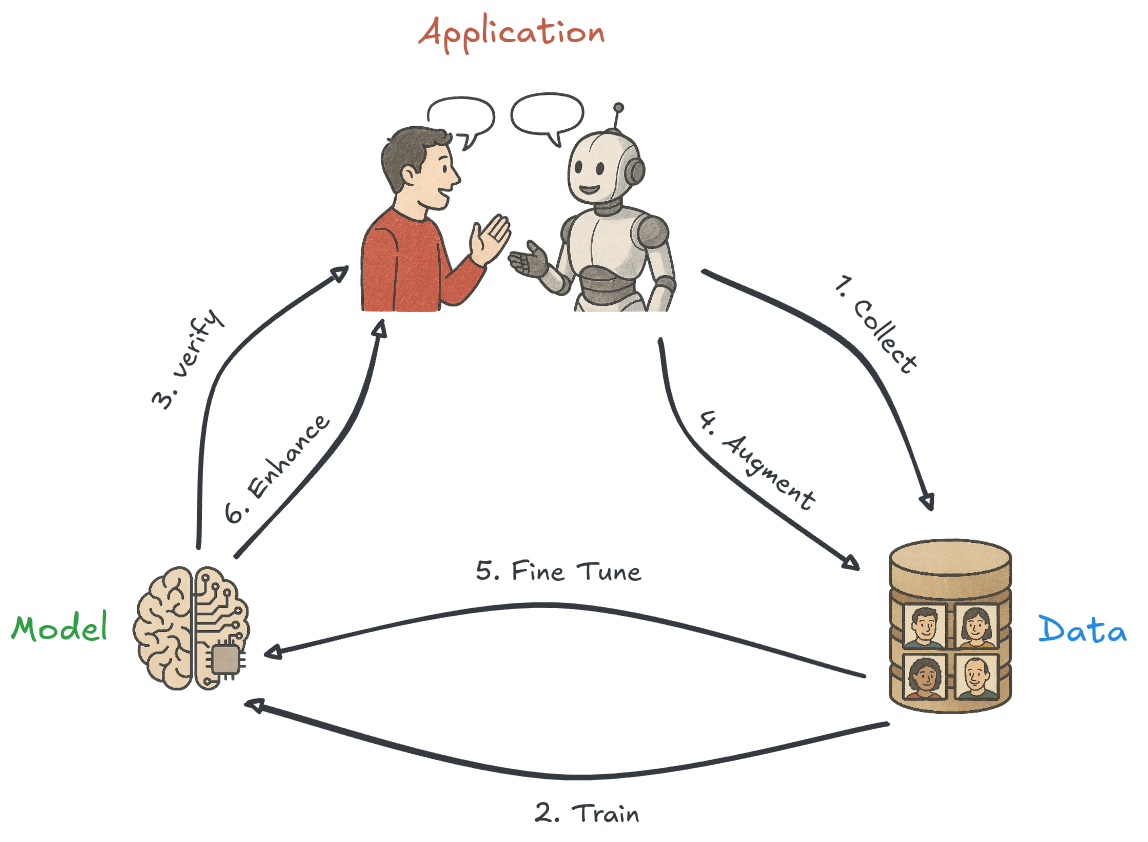
Motivation
I believe it is crucial for humans to interact with robots in a natural way in the future. Currently, Human-Robot Conversations are highly one-dimensional, often resembling simple chatbots. However, the physical form, sensors, and actuators of robots allow for the integration of additional modalities, which can significantly enhance the interaction experience.
Goals
The primary goal of my PhD is to make VVAD and Active Speaker Detection not only robust but also practical for robotics applications. This includes:
- Developing models that are efficient and scalable:
- Creating smaller versions of the models that can run on less powerful hardware, beyond high-performance GPUs.
- Providing accessible implementations:
- Publishing the final implementation as a Python library.
- Offering a ROS2 Node to make the results easily available for robotic systems.
- Packaging the solution as a Docker container for out-of-the-box usability.
By achieving these goals, I aim to bridge the gap between cutting-edge research and practical applications in robotics, enabling more natural and multimodal human-robot interactions.
Publication Plan
Published Papers
The VVAD-LRS3 Dataset for Visual Voice Activity Detection
A. Lubitz, M. Valdenegro-Toro, F. Kirchner
Awarded with Best Student Paper Award
Published: 2021
Presented at: 7th International Conference on Human Computer Interaction Theory and ApplicationsA Bayesian Approach to Context-based Recognition of Human Intention for Context-Adaptive Robot Assistance in Space Missions
A. Lubitz, O. Arriaga, T. Hassan, N. Hoyer, E.A. Kirchner
Published: 2022
Presented at: SpaceCHI 2.0: Human-Computer Interaction for SpaceCobair: A Python Library for Context-Based Intention Recognition in Human-Robot-Interaction
A. Lubitz, L. Gutzeit, F. Kirchner
Published: 2023
Presented at: 32nd IEEE International Conference on Robot and Human Interactive Communication- Improving Human-Robot Communication in Noisy Environments with Visual Voice Activity Detection
A Gopikrishnan, A Auer, L Gutzeit
Published: 2025
Presented at: International Conference on Computer-Human Interaction Research and ApplicationsPlanned Papers
- A Wizard of Oz experiment for Gaze Backchannels